
Daria Dobrycheva is an astrophysicist, a Candidate of Physical and Mathematical Sciences, a senior researcher, and the acting head of the Laboratory of Large-Scale Structure of the Universe at the Main Astronomical Observatory of the National Academy of Sciences of Ukraine.
Daria investigates the morphology of galaxies, seeking rare objects such as galaxies with polar rings and exocomets. Modern telescopes produce vast quantities of data each night, making manual processing impractical. Consequently, Daria and her colleagues in the department were among the pioneers in Ukrainian astronomy to adopt machine learning techniques, enabling algorithms to identify phenomena beyond human comprehension.
We examine the ways in which artificial intelligence is revolutionizing fundamental science, delineate the distinction between exaggerated neural networks and authentic machine learning, and elucidate why humans continue to serve as the principal architects of our comprehension of the cosmos.
 Daria Dobrycheva
Daria Dobrycheva
Daria, let us commence with the current subject of widespread discussion: large language models, image generation, and neural networks. To what extent have these technologies integrated into your routine research activities?
The trend is already quite evident. For instance, we utilize ChatGPT for coding tasks, which proves more efficient than manually consulting manuals. This signifies progress — an era of continuous change. Historically, individuals frequented libraries; however, with the advent of the Internet, library visitation declined due to the accessibility of online information. Presently, we have Google, but asking a chat is quicker. Consequently, the act of “Google-ing’ has been replaced by ‘chatting.”
Has it already established itself as a standard instrument in the field of astrophysics?
There is a significant distinction to be made here. The general understanding of artificial intelligence is, in fact, primarily composed of sophisticated neural networks trained on extensive internet data. However, our focus is on machine learning, which employs a more statistical approach. We work with a limited dataset and utilize specific methodologies tailored to particular tasks. For example, modern smartphone cameras automatically apply smoothing, wrinkle removal, and image enhancement through trained neural networks. Similarly, neural networks perform analogous functions with data. Nonetheless, it is imperative that our samples remain clean and unprocessed, without any form of smoothing or alteration.
In other words, the term “artificial intelligence” broadly encompasses a diverse range of tools. May I inquire as to how you came to utilize these methodologies? After all, your journey toward astrophysics was rather unconventional.
I graduated from Chernihiv Pedagogical University with a highly unusual major: computer science and English education. I was notably inexperienced in English during my school years. A friend of mine recommended that I apply to a teacher-training college, stating, “You are proficient in mathematics, and you are exempt from taking an English exam.” I responded, “Ira, my only knowledge is ‘I go to school number 30.’” She assured me, “You will learn!” I trusted her so completely that I decided to pursue that major. Initially, it was a challenging experience. I earned my scholarship solely to invest it in an English tutor.
Our team was led by Volodymyr Marchenko, an esteemed astrophysicist who had recently defended his doctoral dissertation and secured a modest grant to establish an astronomy center at the university. Consequently, we commenced hosting popular science lectures on astronomy. I found these sessions profoundly captivating, describing them as simply fantastic. Additionally, he informed me that one of his colleagues, Olha Melnyk from Kyiv, was seeking a student capable of analyzing galaxies and classifying their types. This opportunity precisely motivated me to pursue graduate studies.
 Daria Dobrycheva
Daria Dobrycheva
Were you able to gain admission to the university immediately?
It took me three years to achieve this milestone. My prospective supervisor, Iryna Borysivna Vavylova, kindly informed me that I would not be admitted in my first year due to insufficient knowledge. She recommended that I attend certain courses as an auditor at the physics department. Simultaneously, she employed me as an engineer. In comparison with the information technology sector, this position is akin to being a junior scientist. While working as a tutor in Chernihiv, I earned 3,000 UAH, whereas an engineer in Kyiv received 800 UAH. Nonetheless, I was grateful for the accommodation provided by the university. I have always appreciated the small blessings, and in this instance, I found myself with free housing in Kyiv, the realization of my dream to become a scientist beginning to materialize, and I was remunerated for my efforts. What more could I wish for?
I consistently convey to everyone that I am a content individual because I have deliberately chosen to pursue what I love. I have developed an interest in English as well as astronomy.
The classification of galaxies: What is this process, and why do we categorize galaxies into various types?
It is imperative that they be classified, as determining the type of galaxy significantly enhances our understanding. This process is comparable to entering a forest, observing the leaves, and recognizing, “Oh, that’s a birch tree.” We know a lot about birch trees. It’s the same with galaxies.
 Daria Dobrycheva
Daria Dobrycheva
A century ago, Hubble suggested categorizing galaxies into elliptical, lenticular, spiral, barred spiral, and irregular types. However, the challenge concerns the scale. The Sloan Digital Sky Survey (SDSS) monitors the sky and disseminates data to the public biannually. Within the local universe, there are approximately 300,000 galaxies. It is simply unfeasible to examine all of them unaided. Notably, a portion of this work was carried out by volunteers through the Galaxy Zoo initiative.
Therefore, will additional data continue to be collected henceforth?
Significantly more data is generated. The Sloan Digital Sky Survey (SDSS) supplied 200 gigabytes of data nightly. Its successor, the Large Synoptic Survey Telescope (LSST), which is currently under development, will deliver 20 terabytes of data per night. Three years prior, I attended a workshop in Portugal where a representative of the LSST explained that, whereas with the SDSS one could easily visit the website and download the database, this would not be feasible with the LSST. Even to extract any data, it will be necessary to generate specialized queries using artificial intelligence.
 Daria Dobrycheva
Daria Dobrycheva
How does the system for accessing data from these telescopes operate?
Large telescopes are highly costly, and no individual nation typically constructs one independently. Instead, multiple countries collaborate by pooling their resources and jointly undertaking the construction, thereby securing priority access to the observational data. After an interval of six months to one year, the data is subsequently made publicly accessible. Additionally, there exists a subscription model, similar to Netflix, which allows users to access the data more promptly. My supervisor, Iryna Borysivna Vavylova, has long contemplated how our institution might obtain such access, considering that our nation lacks sufficient financial resources to contribute comparably. We applied for a grant from the Simons Foundation; however, regrettably, our application was unsuccessful. We remain committed to pursuing alternative opportunities.
Currently, we are actively submitting proposals for various projects. Although two proposals were not successful, one was approved. We are maintaining our stability and progressing steadily.
 Daria Dobrycheva
Daria Dobrycheva
In spite of these numerous challenges, your team has successfully classified hundreds of thousands of galaxies. Could you please elaborate on the methods employed to train the machine to differentiate between various types of galaxies?
I consistently illustrate this concept with a straightforward example. How does a child distinguish a cow from a horse? Our brains have been trained to identify specific patterns that are exclusive to cows and others that are exclusive to horses. It is necessary to instruct a machine to perform the same task.
We selected 6,000 galaxies from our sample of 300,000, examined them visually, and classified them definitively as elliptical or spiral. Subsequently, we analyzed their photometric data, which pertains to the characteristics of the light emitted by these galaxies. The Sloan Digital Sky Survey (SDSS) employs five distinct photometric filters, enabling the derivation of color combinations, radii, and brightness profiles. By assessing the distribution of light from the center to the periphery, substantial insights into the galaxy classification can be obtained.
Which machine learning methods are appropriate for this application?
We employed various machine learning techniques, such as Random Forest. Recall those astrology quizzes in adolescent magazines: are you a Leo, a Cancer, or a Pisces? While I do not subscribe to astrology, this analogy comes to mind. The underlying concept is analogous: the system poses a question, such as whether a color is more yellow or blue, with a yes or no response. After evaluating all questions, it deduces the classification. A single decision tree of this nature may err; however, when multiple trees are combined and reach a consensus through voting, the overall accuracy improves.
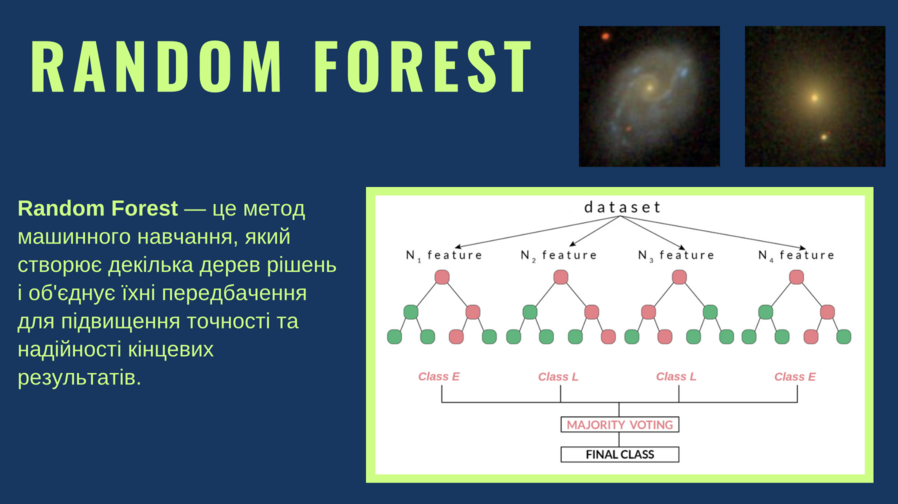 The “Random Forest” method
The “Random Forest” method
There exists a methodology referred to as the “K-nearest neighbors” technique. This approach involves analyzing a newly observed galaxy and comparing it to known galaxies based on their parameters — specifically focusing on these parameters rather than physical distance. If the galaxy’s closest counterparts are identified as spiral galaxies, then it is highly probable that the galaxy in question is also a spiral galaxy.
 The K-nearest neighbors method
The K-nearest neighbors method
There exists a method known as the support vector machine. Consider a scenario where red and blue balls are placed on a table, and the objective is to draw a line that distinctly separates them. Occasionally, this task is straightforward; however, at times the objects are so intricately mixed that separation in a single dimension becomes infeasible. In such cases, we elevate the dimensionality, transitioning from one-dimensional to two- or three-dimensional space. Within this expanded space, it becomes feasible to draw a plane that distinctly distinguishes elliptical objects from spiral ones. Even if some objects are misclassified, the algorithm treats these instances as exceptions, thereby preventing distortion of the overall classification and ensuring that the results remain sufficiently accurate.
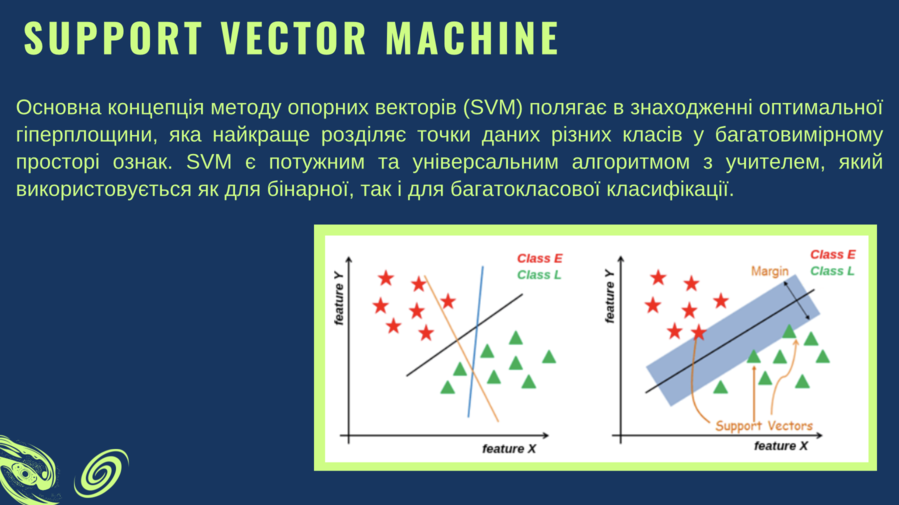 Support vector machine method
Support vector machine method
Additionally, we employed logistic regression and naive Bayes methods. The first technique functions by inputting all of the galaxy’s parameters into a mathematical model, which subsequently outputs either a 1 or a 0, indicating whether the galaxy is spiral or elliptical. The second approach is grounded in probability theory: given a set of characteristics, it computes the likelihood that the galaxy belongs to one category or another.
On what criteria does the machine base its assessment, and from where does it obtain its benchmark for comparison?
This process is referred to as supervised learning. Having personally examined 6,000 galaxies, we possess precise knowledge regarding their classification as elliptical or spiral. This is analogous to the last column in an Excel spreadsheet where the answer has been pre-filled. We utilize this data to train the machine learning model, which then extrapolates the results to a dataset of 300,000 galaxies.
And you know what is important? We could not simply select the nearest and most luminous galaxies, train the model using them, and then generalize to more distant galaxies. That approach would have been inappropriate. Therefore, we chose the galaxies randomly from across the entire spectrum of distances and brightness levels. In conclusion, the Random Forest and support vector machine methods provided the highest accuracy — exceeding 95%.
Do machines ever make mistakes?
For instance, if a spiral galaxy is encircled by other galaxies, their gravitational forces may strip gas from it. Consequently, it ages more rapidly, assumes a yellow hue, and the data analysis may classify it as elliptical, despite its spiral morphology. Additionally, if photometric measurements only encompass the central region of a large galaxy, which is inherently more yellow than the arms, the system may interpret the yellow core as indicative of an elliptical galaxy.
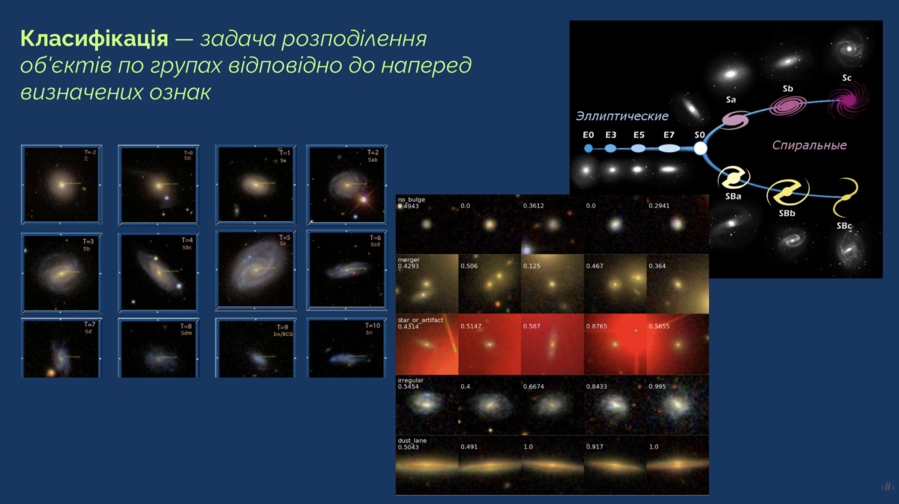 Classification of galaxies
Classification of galaxies
You referenced the Galaxy Zoo project, wherein volunteers from the general public contributed to the classification of galaxies. Could you elaborate on how this pertains to your professional endeavors?
Every major telescope project involves collaboration with volunteers. When the Sloan Digital Sky Survey (SDSS) was initiated, the collected data were made accessible to the public. Volunteers were provided with examples, such as the appearance of spiral galaxies, elliptical galaxies, barred versus non-barred galaxies, and irregular galaxies. Individuals from across the globe, driven by curiosity, would log in, assist astronomers, analyze the data, and record observations. Essentially, this process resembles data annotation akin to CAPTCHA, where the task is to identify objects, such as a cup or a traffic light.
Were you able to utilize these results to train the neural network?
Not immediately. Out of our 300,000 galaxies, 170,000 had already been classified by volunteers in Galaxy Zoo, while 140,000 remained unclassified. It might appear straightforward to utilize the 170,000 classified galaxies for training purposes; however, we elected to conduct a preliminary analysis. Examination of the photometric data for both samples revealed that brighter galaxies were preferentially selected for the Galaxy Zoo project. This is understandable, as the average individual generally struggles to distinguish the dimmer galaxies in the images.
We developed a specialized neural network, the Adversarial CNN, intended to discern differences between two datasets. The model indicated that these subsets (comprising 140,000 and 170,000 samples, respectively) were approximately 90% distinct. Consequently, this implies that the volunteer annotations could not be directly employed for training purposes.
Could you please explain how you managed to extricate yourself from that situation?
We adopted an alternative methodology. From Galaxy Zoo, we selected solely those galaxies that had received a substantial number of votes from volunteers — not merely two, but potentially ten. In essence, we identified the most dependable results. Subsequently, we employed a neural network to exclude those galaxies that most closely resembled our unclassified galaxies based on their attributes. Ultimately, only 9,000 galaxies remained.
Due to the insufficiency of initial data, we implemented data augmentation techniques. This process involves taking a single image — understanding its category — and generating numerous variations by introducing noise, rotating it at various angles, and applying slight distortions. Consequently, from an initial set of 9,000 images, we expanded our sample size significantly. We employed multiple neural network architectures and determined that DenseNet, a neural network optimized for image recognition, delivers the most accurate results, achieving a 96% accuracy rate. Subsequently, it was utilized to classify the remaining 140,000 galaxies into five categories: fully circular, semi-circular, cigar-shaped, barred, and spiral.
Which types caused the most problems?
The machine encountered the greatest difficulty with cigar-shaped objects. It took us one month to determine the reason, which was revealed to be their visual resemblance to spiral galaxies observed from the side. Notably, we discovered a discussion on the Galaxy Zoo forum that addressed this particular issue. Statistical analysis showed that volunteers most frequently erred in identifying cigar-shaped objects. Consequently, if the initial sample contains inaccuracies, the subsequent results will also be compromised. As scientists, it is imperative that we seek validation before making definitive claims.
 Galaxy Zoo
Galaxy Zoo
Nevertheless, we succeeded in achieving another noteworthy outcome. We employed the classification results and the k-nearest neighbors algorithm within a multi-parameter space to generate more comprehensive catalogs. Galaxy Zoo encompasses approximately 32 subcategories, including irregular galaxies, merging systems, objects exhibiting dust lanes, diverse spiral arm configurations, the presence or absence of bars, rings, and other classifications.
Therefore, you not only categorized the galaxies according to their primary classifications but also conducted an in-depth analysis within each category. That is commendable. Were you able to identify anything genuinely unusual among those hundreds of thousands?
One of our most intriguing subjects at present is galaxies featuring polar rings. Universe Space Tech has previously addressed this phenomenon. To comprehend this concept, it is essential to consider the events that occur when two galaxies undergo a collision. Allow me to pose a question: will the stars also collide during such an event?
To the best of my understanding, the answer is negative.
Indeed, this is correct. The immense distances between stars are so extensive that they appear to merge visually. Throughout its history, the Milky Way has assimilated numerous smaller galaxies, with no collisions occurring. Consequently, when two substantial galaxies merge, a polar ring may develop. This phenomenon involves a ring of gas and stars orbiting the primary galaxy at an angle relative to its plane. Essentially, one galaxy has enveloped the other.
Several hypotheses have been proposed regarding the mechanisms behind this phenomenon. The first posits that one galaxy progressively attracts matter from another, a process known as accretion. The second suggests that two galaxies fully merge at a specific angle. The third, which is the most unconventional, proposes that at the boundary between two voids and a slender filament, gas can be extruded at a particular angle and spiral into the galaxy. Each hypothesis is supported by its own calculations; however, such galaxies are exceedingly rare in the universe. They represent exceptionally infrequent celestial objects.
How did you find them?
Initially, all available catalogs were collected, with the oldest dating back to 1990. This process resulted in a total of 355 candidates. Upon review, it was observed that a considerable number of these were included erroneously. Historically, telescopes possessed lower resolution capabilities, leading scientists to sometimes misinterpret features — such as perceiving rings that were not actually present. In certain instances, background galaxies were superimposed, while in others, dust created the illusion of a ring. Additionally, some misidentifications arose from irregular galaxy shapes or merger phenomena mistaken for rings. After applying rigorous filtering, only 87 candidates were confirmed as reliable.
For a neural network, this constitutes an exceedingly small sample size. We attempted to augment the dataset by generating artificial images of such galaxies utilizing the GALFIT program. However, we encountered an overfitting issue, as all the synthesized galaxies were overly similar, leading the neural network to memorize the training examples. Despite this, it successfully learned to identify the ring pattern itself.
There was a humorous incident when we became genuinely enthusiastic upon believing we had discovered a new galaxy featuring a polar ring. However, it was subsequently determined to be an arm of a spiral galaxy overlapping with an elliptical galaxy. We encountered three such false positives. Nevertheless, we also made some genuine discoveries, including a galaxy with a small ring angle, which we verified, and another particularly intriguing case where matter from one galaxy appears to be winding itself around another. This latter observation serves as one of the confirmations of the accretion theory.
We also identified galaxies featuring two rings, which may suggest that the polar ring remains in the process of formation. This presents a compelling question regarding their evolution: why do such structures exist at all, and why are they so uncommon?

We frequently discuss visual observations, shapes, and colors. Is this sufficient for comprehending the nature of an object? Are observations across other regions of the electromagnetic spectrum — such as infrared — considered in the analysis?
This constitutes a significant inquiry. In the context of neural network search methodology, visual features were indeed employed. However, upon identifying an intriguing object, a transition was made to multi-wavelength analysis. In our department, Olena Kompaniiets specializes in this field. A dedicated software application named CIGALE is utilized, which integrates physical models of the evolution of stellar components, dust, gas, and black holes across various segments of the electromagnetic spectrum.
Regarding one of the galaxies exhibiting a polar ring that we identified, the model indicated a significant burst of star formation in the past. If such a burst occurs suddenly and endures for a brief duration, it may suggest a galactic merger. However, in this instance, the process was relatively prolonged, characterized by a gradual escalation in the rate of new star formation. This observation, therefore, points towards accretion, whereby matter was incrementally accumulated. Additionally, we assessed the galaxy’s degree of isolation from neighboring galaxies, and it was determined that these neighbors did not exert any influence. In summary, we have increasingly substantiated the hypothesis that the polar ring in this galaxy was formed through the process of accretion.
Galaxies exist on a colossal scale. However, do you utilize machine learning for matters closer to home, within star systems?
My colleague, Maksym Vasylenko, and I were invited to participate in a project focused on the search for exocomets. Maksym, who is an exceptionally talented individual, has been serving in the military since the inception of his career. He is nearing the completion of his dissertation; however, circumstances have often led many of our scientists to defend their country rather than their academic work. Consequently, we received an invitation from the Substellar and Planetary Systems Physics Department, a neighboring department, which specifically sought our expertise in machine learning.
What is the technical mechanism behind this process? How can one identify a comet in proximity to another star?
The underlying principle here differs. When a planet occludes a star, its shape is spherical, and the resulting decrease in brightness is symmetrical. In contrast, a comet possesses a tail, leading to an asymmetrical decline in brightness. Furthermore, this phenomenon is represented not as a visual image but as a time series. In essence, it constitutes a fundamentally different type of data, thereby necessitating distinct analytical approaches.
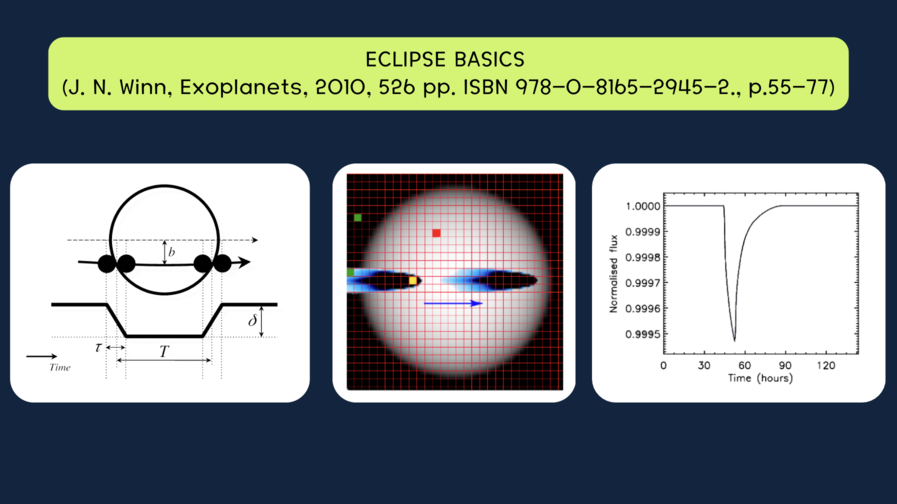 Search for exocomets
Search for exocomets
Therefore, does each category of problem necessitate a distinct approach?
Indeed, numerous methodologies are accessible in contemporary practice. We assess the available data to determine the most suitable approach accordingly. For instance, we employed Random Forest for exocomets; however, it was trained on entirely different data rather than galaxies. The nature of the data involved is indeed a significant factor.
What is the significance of identifying exocomets initially?
Envision a nascent star recently formed. Encircling it is a protoplanetary disk, within which planets are already coalescing, and numerous fragments are suspended. Some of these fragments are comets — primarily composed of ice and gas. Should a comet collide with a young terrestrial planet, the ice and gas accrete onto the surface, melt, and are retained by gravity, preventing their escape into space. This process gradually contributes to the formation of an atmosphere. In essence, the detection of exocomets would serve to substantiate the theory of planetary atmosphere development.
However, have very few exocomets been discovered to date?
Yes, only a few dozen are known. This remains an exceedingly limited sample size. The preliminary theoretical calculations regarding the appearance of exocomets and their observational signatures were conducted as early as 1999, despite the absence of pertinent data at that time. Subsequently, the Kepler and TESS telescopes yielded the initial observational results.
We elected to employ a strategic methodology. We simulated the brightness curve of a star in the event of a passing comet, subsequently superimposing this simulated data onto authentic observational data from various stars in a random manner. This process enabled us to generate a training dataset with definitive labels indicating the presence or absence of a nearby comet. The model was then trained using this dataset.
The primary challenge lies in the fact that a comet’s luminosity is significantly fainter than that of a planet, leading to its signal being obscured by noise. We utilized a parameter designed to filter out this noise. When noise levels are minimal, the signals are clearly discernible. However, in real data, the prevalence of noise renders the results borderline, approximately a 50-50 probability split. Although this may seem unfavorable, it is, in fact, advantageous for our purposes, as we identified 32 curves with a likelihood of over 80% for the presence of an exocomet. These were subsequently reviewed manually, with planetary transits and noise artifacts systematically excluded, leaving us with two curves that potentially indicate an exocomet transit.
In our examination of the star Beta Pictoris — a young system characterized by numerous debris disks—we successfully confirmed the existence of exocomets. Additionally, Scientific American reported the discovery of new exocomets by Ukrainian scientists. Our research paper, which includes these findings, was accepted for publication by one of the world’s premier astronomy journals. Notably, the acceptance date was February 25, 2022. The final revisions prior to publication were meticulously conducted by our team leader, Yakov Pavlenko, amidst the most challenging days encountered by our country.

The scope of tasks is commendable. Is there any additional work you are currently engaged in?
There is an additional intriguing question — one that is somewhat existential in nature. Initially, we contemplated the existence of other planets and subsequently discovered exoplanets. Following this, we began searching for comets orbiting other stars, leading to the identification of exocomets. Currently, the pertinent question is: Does a twin of our Milky Way galaxy exist elsewhere in the universe? Specifically, a galaxy analogous to our own in which life could theoretically thrive. For instance, galaxies with active nuclei emit such intense radiation that the potential for life on their planets is considered improbable. We have secured a grant from the National Research Foundation and are actively engaged in research on this subject, utilizing machine learning methods.
Furthermore, this study presents an intriguing reconstruction of the Milky Way’s line of sight. As residents within the core of our galaxy, the Milky Way, our perspective is inherently limited in observing regions beyond it. Iryna Borysivna Vavylova, the head of the department where I am employed, proposed a methodology: understanding the spatial distribution of galaxies allows for the exclusion of certain data, training a machine learning model to reconstruct it, and, if successful, extending this reconstruction to the region obscured by our galaxy. This process is analogous to mending a tear in fabric: knowing the pattern enables the recreation of the missing section.
Does machine learning accommodate scientific intuition? If algorithms are becoming increasingly precise, isn’t scientific intuition diminishing in importance?
I do not believe so. Scientific intuition remains a vital aspect of scientific progress. An illustrative example is documented in your publication: during the Soviet era, a scientist named Serhii Kostiantynovych Vsesviatskyi, who was affiliated with the physics department, predicted that Jupiter would possess rings similar to those of Saturn. Despite skepticism due to the lack of observable evidence and limited telescope resolution at that time, subsequent data from the Voyager spacecraft confirmed the existence of such rings. This exemplifies scientific intuition — an intrinsic development that occurs within individuals who continuously engage with data and information.
I share the same observation. When I evaluate a student’s paper, I can often discern that it was generated by ChatGPT. Although I may not always be able to articulate the specific reasons, an intuitive sense persists. Nevertheless, when an individual employs ChatGPT appropriately, the resulting text becomes difficult to distinguish from that authored personally by the student.
Regarding students, it is noted that you serve as a juror for the Junior Academy of Sciences of Ukraine in the Astronomy Competition. Do you observe any influence of AI on the quality of the projects?
 Daria Dobrycheva
Daria Dobrycheva
A few years ago, instances of plagiarism were prevalent in their work, as students frequently copied text from the internet without adequate consideration. Once we elucidated the reasons against such practices, their work showed improvement. However, recent observations reveal that their writing often appears to be generated by ChatGPT. Initially, I presumed the students’ lack of effort was the primary issue. Nevertheless, in personal conversations, they articulate concepts far more effectively than in their written assignments. When I inquire, “Why couldn’t you write this yourselves?” they comprehend the content entirely, yet find it simpler to seek assistance from the model rather than to develop the content independently. The core concern does not lie with the technology itself, but with the approach towards its use. A language model should be regarded merely as a tool; anyone genuinely interested in learning will utilize it to their benefit.
This is a prevalent issue in contemporary society. An increasing number of undergraduate and graduate students are utilizing artificial intelligence to compose their theses and dissertations. Do you believe there exists a risk that the overall standards of training for future generations of researchers may diminish?
I believe this constitutes a component of human advancement. Whenever a novel development arises, individuals eager to acquire knowledge will pose appropriate inquiries. Conversely, those less inclined to learn will tend to be unproductive. The intellectually capable will continue to increase their understanding. When automobiles were first introduced, there was widespread concern that they would displace employment. However, this did not occur. We continue our efforts, working and adapting accordingly.
 Daria Dobrycheva
Daria Dobrycheva
An additional pertinent inquiry pertains to the current status of personnel. Numerous scientists are presently either engaged in military service or have departed from Ukraine. Is there an evident deficiency in manpower?
The issue is highly conspicuous. Additionally, there exists a significant problem concerning demographic composition. The population of young individuals is exceedingly limited; only a small number of individuals are of my age or younger. Consequently, the demographic primarily consists of the older generation.
A statistical correlation exists between a nation’s expenditure on scientific research as a percentage of its Gross Domestic Product (GDP) and the influence this investment has on its economic development. To effect at least a minimal impact, an allocation of 1.7% of GDP is required. Countries such as Germany, France, the United Kingdom, and the United States allocate between 2% and 3% of their GDP to scientific endeavors, thereby experiencing tangible effects on their economic growth. Conversely, in our country, the allocation was merely 0.17% prior to the extensive invasion. For instance, I am a senior research fellow whose salary ranges from 13,000 to 14,000 hryvnias; the remainder of the income is obtained through supplementary grants. To cover personnel salaries and the utility expenses of the observatory, an annual budget of approximately 32 to 35 million hryvnias is necessary. The government allocates roughly 20 million hryvnias. Consequently, we are able to cover utility costs, fund half of our salaries, and the remainder depends on our success in securing additional grants.
Therefore, the initial inquiry does not pertain to artificial intelligence or models; rather, it concerns whether the government possesses an interest in scientists altogether. That constitutes the preliminary step.
 Daria Dobrycheva
Daria Dobrycheva
Can language models at least partially compensate for this deficiency in scientific personnel?
Models cannot replace scientists. Human involvement remains essential for operating these models and posing pertinent inquiries. Without human intervention, they merely represent inert tools. Nonetheless, there are individuals who persistently refuse to relinquish their efforts and continue this work with steadfast dedication.
Olena Kompaniiets, a colleague of mine, serves as the project coordinator for Science Kids within the framework of InScience. They are responsible for identifying scientists and tailoring their lectures to suit children aged 8 to 12. Olena states that the project has been ongoing for several years, and the children are increasingly requesting more detailed information, saying: “Tell us the same thing, but with formulas, because this isn’t enough for us anymore.” When complex topics are elucidated to children in an engaging manner, their natural curiosity is stimulated. Moreover, it should be noted that no ChatGPT can substitute for a human presenter in this context. Human interaction remains indispensable.
It is evident that I, likewise, was enamored with the field of science, dedicating considerable effort and time towards the pursuit of becoming a scientist. I anticipate that similar aspirations will inspire future generations. Those with a desire to learn shall do so, while others may depend on models to simulate intelligence.
 Daria Dobrycheva
Daria Dobrycheva
Two years ago, the observatory team inaugurated the Main Astronomical Observatory of the National Academy of Sciences of Ukraine during the final week of the summer season. This program convenes students, graduate students, and young scientists from across Ukraine, and we have successfully invited researchers from nearly all of the country’s astronomical institutions, as well as international speakers. We take pride in having secured funding through the collaboration with small Ukrainian enterprises.
Therefore, is it contingent upon the individual and their willingness to progress?
That is precisely correct. Additionally, it is essential to have a plan of action. Prior to the large-scale invasion, my husband inquired, “What is your plan for the year?” I dismissed this inquiry at the time, responding, “What plans?” Subsequently, the war commenced, and it appeared that planning was futile. However, over time, I came to understand that the contrary is true. A plan aids in maintaining focus, preserving mental stability, and pursuing one’s passions. I study galaxies, occasionally comets, and find great satisfaction in this. As long as a plan exists and there is a genuine eagerness to learn, scientific progress will continue unabated.